
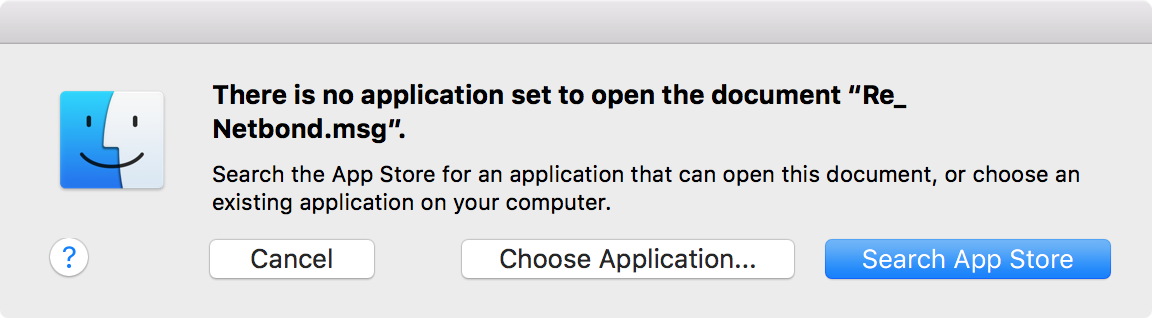
I received a .msg file attachment to an email message I received with Microsoft Outlook for Mac, which is part of Microsoft Office 2016 on my MacBook Pro laptop. When I double-clicked on the attachment in Outlook to view the contents of the file, I saw "There is no application specified to open the document Re_ Netbond.msg."

And also a window giving me an option to "Search App Store" with the message "Search the App Store for an application that can open this document, or choose an existing application on your computer."
I saved the attachment to the system's disk drive and checked on the file type with the file command, which reported it was a Composite Document File V2 (CDF V2) document.
$ file Re_Netbond.msg Re_Netbond.msg: CDF V2 Document, No summary info $
When I tried displaying the contents of the the file with the more command, I was warned the file might be a binary file and when I chose to display the conents anyway, the output was unreadable to me.
Since I didn't have any application on the laptop, which runs OS X El Capitan, to view msg files, I decided to perform a Google search for a Python script that would be able to decode the message. I found ExtractMsg.py, currently at version 0.3, on GitHub. The Readme file for the script notes:
Extracts emails and attachments saved in Microsoft Outlook's .msg files
The python script ExtractMsg.py automates the extraction of key email data (from, to, cc, date, subject, body) and the email's attachments.
To use it
python ExtractMsg.py example.msg
This will produce a new folder named according to the date, time and subject of the message (for example "2013-07-24_0915 Example"). The email itself can be found inside the new folder along with the attachments. As of version 0.2, it is capable of extracting both ASCII and Unicode data.
The script uses Philippe Lagadec's Python module that reads Microsoft OLE2 files (also called Structured Storage, Compound File Binary Format or Compound Document File Format). This is the underlying format of Outlook's .msg files. This library currently supports up to Python 2.7 and 3.4.
The script was built using Peter Fiskerstrand's documentation of the .msg format. Redemption's discussion of the different property types used within Extended MAPI was also useful. For future reference, I note that Microsoft have opened up their documentation of the file format.
So I tried that script. When I tried to decode the .msg file, though, I saw the error message below:
$ ./ExtractMsg.py.sav Re_Netbond.msg
Error with file 'Re_Netbond.msg': Traceback (most recent call last):
File "./ExtractMsg.py.sav", line 539, in <module>
msg.save(toJson, useFileName)
File "./ExtractMsg.py.sav", line 434, in save
f.write(self.body)
UnicodeEncodeError: 'ascii' codec can't encode character u'\u2019' in position 172: ordinal not in range(128)
$The script did create a directory with files in it, though. The directory name was today's date followed by the file name. Within that directory was a message.text file and another directory.
$ ls -ldg 2018-02-02_1317\ Re\ Netbond/ drwxr-xr-x 4 1286109195 136 Feb 2 15:50 2018-02-02_1317 Re Netbond/ $ ls -l 2018-02-02_1317\ Re\ Netbond/ total 8 -rw-r--r-- 1 jasmith1 1286109195 217 Feb 2 15:50 message.text drwxr-xr-x 58 jasmith1 1286109195 1972 Feb 2 15:50 raw $
The message.text file contained the "from", "to", "subject" and "date" lines for the email message contained in the .msg file, but the body text was missing. The error message that was produced when I ran the script referenced line 434 in the script:
File "./ExtractMsg.py.sav", line 434, in save
f.write(self.body)I was able to eliminate the error by substituting the following 3 lines of
code for the line containing f.write(self.body) based on
the suggestion by agf at
UnicodeEncodeError: 'ascii'
codec can't encode character u'\xa0' in position 20: ordinal not in range(128)
:
bodytext = self.body
bodytext = bodytext.encode('utf-8')
f.write(bodytext)When I deleted the directory previously created by the script and all its contents and reran the script, I didn't see any error message.
$ ./ExtractMsg.py Re_Netbond.msg $
The output directory then contained only the message.text file and that file contained the "from", "to", "subject", and "date" for the email message contained in the .msg file and, this time, the body of the message as well.
After that worked, I then looked at the
pull requests
for the project on GitHub and found
Tyler Williamson had submited a pull
request 3 days ago,
hange str() to .encode('utf-8') to avoid UnicodeEncodeError regarding
the error. He had changed the self.write(self.body) line to
f.write(self.body.encode('utf-8')). When I used his version
of the script, it worked fine. As with my version, I saw "^M" at
the end of lines in the body of the message in the message.text
file when I edited it with the vi text editor. Looking at the contents of the
file with the od command, I could see that there was a
carriage return
and newline,
aka line feed, at the end of each line, i.e., \r \n, which is the
way Microsoft Windows systems deal with line endings, whereas OS X uses just a
carriage return
character, i.e., hexadecimal 0D - see OS X Line Endings. I was
able to get rid of the ^M characters using the vi
editor command below. Note: you have to use Ctrl-v
Ctrl-m to get the ^M rather than hitting the
^ and M keys.
:1,$ s/^M//g
Until Matthew Walker incorporates the change into his version of the script, you can avoid the unicode error message by using Tyler Williamson's version available at msg-extractor. I've also placed copies of the zip file from his repository and just the script at the links below:
msg-extractor-master.zip
ExtractMsg.py
Note: to use either version, you will need to have the
olefile
Python package installed. That package can be installed on a Mac
OS X system with sudo easy_install olefile - see
Using olefile to obtain
metadata from an OLE CDF V2 file or with pip,
if you have that
package manager installed.
I tested the script on an OS X system with Python 2.7.10 installed.
Related articles:

