Mon, Mar 31, 2014 11:03 pm
Determining the boot disk for an OS X system
The
bless command, which can be run from a Terminal window,
can be used to determine the boot disk on an OS X system:
$ bless --info --getBoot
/dev/disk0s2
If you are interested in more details for that drive, you can use the
diskutil info command followed by the drive's designation.
E.g.:
$ diskutil info /dev/disk0s2
Device Identifier: disk0s2
Device Node: /dev/disk0s2
Part of Whole: disk0
Device / Media Name: Customer
Volume Name: Macintosh HD
Escaped with Unicode: Macintosh%FF%FE%20%00HD
Mounted: Yes
Mount Point: /
Escaped with Unicode: /
File System Personality: Journaled HFS+
Type (Bundle): hfs
Name (User Visible): Mac OS Extended (Journaled)
Journal: Journal size 24576 KB at offset 0x1119b000
Owners: Enabled
Partition Type: Apple_HFS
OS Can Be Installed: Yes
Media Type: Generic
Protocol: SATA
SMART Status: Verified
Volume UUID: A140B2C6-4C4F-3B14-B179-C1A7FE0325D4
Total Size: 249.2 GB (249199599616 Bytes) (exactly 486717968 512-Byte-Blocks)
Volume Free Space: 56.4 GB (56438132736 Bytes) (exactly 110230728 512-Byte-Blocks)
Device Block Size: 512 Bytes
Read-Only Media: No
Read-Only Volume: No
Ejectable: No
Whole: No
Internal: Yes
Solid State: No
[/os/os-x]
permanent link
Sun, Mar 30, 2014 10:38 pm
OnlineWebCheck HTML Validator
I've been using the
Markup Validation Service provided by the World Wide Web
Consortium (W3C) to check for errors in the HTML code for webpages on
this site, but recently came across another such free service, the
Free HTML & CSS Validation Service at OnlineWebCheck.com.
Like the W3C service, you can provide a URL for your website to be analyzed
for HTML errors. The service will display any errors found on a submitted
page and warnings for page elements that aren't errors, but which may
deserve closer scrutiny. The online service is free and allows you to
check URLs one-by-one. The service uses
CSE HTML Validator Pro,
which is software that runs on Microsoft Windows systems, or Linux and Mac
OSX with Wine. There is a free version of that software available for
download as well as paid versions with more features - see
Compare CSE HTML Validator Editions. I haven't yet tried that software
on a Microsoft Windows system yet, though, but have only used the online
validation service.
I found the service yesterday when the W3C service wasn't responding.
One warning I received for a submitted page was for the lack of a
language specification within the <HTML> start tag. The warning was:
The natural primary language is not specified. It is highly recommended
that the "lang" and/or "xml:lang" (for XHTML) attributes be used with
the "html" element to specify the primary language. For example, add
the attribute lang="en" for English or lang="fr" for French. Specifying
the language assists braille translation software, speech synthesizers,
translation software, and has other benefits.
<html>
I had been including the following within the <head> section:
<meta name="language" content="english">
The OnlneWebCheck.com validator noted in regards to it, though:
Though the W3C validation service had never issued any warnings nor
errors related to the lack of inclusion of the language attribute within
the <HTML> tag or use of the meta tag, at the W3C site
at
Specifying the language of content: the lang attribute
webpage, I found:
Language information specified via the
lang
attribute may be used by a user agent to control rendering in a
variety of ways. Some situations where author-supplied language information may
be helpful include:
- Assisting search engines
- Assisting speech synthesizers
- Helping a user agent select glyph variants for high quality typography
- Helping a user agent choose a set of quotation marks
- Helping a user agent make decisions about hyphenation,
ligatures, and spacing
- Assisting spell checkers and grammar checkers
The recommendation made for assisting search engines and browsers to
determine the language for webpages is to include the language attribute
within the <html> tag as shown below:
<html lang="en">
...
</html>
Or for XHTML:
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
...
</html>
So, I decided to modify the template that I use for pages to include the
language attribute within the <html> tag, i.e., to use
<html lang="en">, and to include the attribute within
the <html> tag for Blosxom's head.html file.
If a page is in another language than English, the appropriate code
can be chosen from the
ISO 639-1 two-letter language codes.
ISO 639-1 defines abbreviations for languages. In HTML and XHTML they can be
used in the lang and xml:lang attributes.
[/network/web/design]
permanent link
Sat, Mar 29, 2014 4:24 pm
Google Analytics Add-on for Google Sheets
If you use
Google
Analytics, for monitoring your website, Google now provides an
add-on for Google Sheets, which is Google's equivalent to Microsoft Excel,
available through Google Docs, that allows you to incorporate Google Analytics
data within a Google Sheets worksheet.
[ More Info ]
[/network/web/services/google]
permanent link
Sat, Mar 29, 2014 10:19 am
Cell Padding in a Table
There are multiple ways to add padding around text
within cells in a table. Specifying
<table
cellpadding="ypx"> with
y
representing the number of pixels of padding will add padding to the left,
right, top, and bottom of the text. If you only wish to have additional
padding at the left and right of the text, you can do so by
CSS, e.g.:
<style type="text/css">
.padded {padding-left: 10px; padding-right: 10px;}
</style>
You can then apply the class "padded" to each td in the
table.
[ More Info ]
[/network/web/design]
permanent link
Fri, Mar 28, 2014 10:12 pm
Problem with Blosxom calendar cache
I use the
Calendar Plugin for Blosxom on this site. When I checked the site
with the
Xenu Link Sleuth tool, which reveals broken links, today I found it
reporting errors for urls with "//" in the directory path in the URL.
It took me a few minutes to realize that the errors were due to the
calendar displayed for the blog that points to prior entries.
When I looked at the URLs for various days on this month's calendar,
I saw that the links were all appearing similar to the following one:
http://support.moonpoint.com/blog/blosxom/2014/03//RS=%5EADAZpNNfKrcEOr1DFixlJAHJ_euLow-/2014/03/04/2014/03/2014/03/01/
They had "RS=" and "euLow-" followed by repetitions of the year
and month in the URL. I knew that the links had been appearng normally, so
I suspected the problem was caused when I posted an entry this morning.
Sometimes when I've worked on something previously, but not yet posted it,
I will change the time on the file associated with the entry to point to the
date and time I worked on it or when I edit an entry I may set its time
stamp to the original date and time after I've finished editing it. I had
done that this morning, so I suspected there was a problem with the
calendar's cache file, .calendar.cache, which is located
in the Blosxom plugins state directory, plugins/state. The
file can be deleted; it will be recreated automatically when the Blosxom
blog is viewed again. I deleted the file and refreshed the page in the browser
with which I was viewing the site and all of the links for the calendar
then appeared normally.
[/network/web/blogging/blosxom]
permanent link
Fri, Mar 28, 2014 9:22 pm
Xenu Link Sleuth
When I checked the error log for this site this morning, I noticed an
entry pointing to a nonexistent file on the site, which led me to check
the Apache CustomLog file to look for information on why someone might
have followed a link to a file that never existed on the site. I didn't
discover the source of the incorrect link, but in the process of checking
for that incorrect link I found a very useful tool, Xenu Link Sleuth, that
revealed a signficant problem with the site due to a change I made this
morning and pointed out broken internal links on the site.
[ More Info ]
[/network/web/tools]
permanent link
Fri, Mar 28, 2014 10:46 am
Determing the NTP servers in use on a Mac OS X system
If you need to know the Network Time Protocl (NTP) server in use on a Mac
OS X system you can use the command
systemsetup -getnetworktimeserver
or you can look at the contents of the
/etc/ntp/conf
file.
$ systemsetup -getnetworktimeserver
Network Time Server: ntp.example.com
$ cat /etc/ntp.conf
server ntp.example.com minpoll 12 maxpoll 17
server time.apple.com
The minpoll and maxpoll values specify the minimum and maximum poll
intervals for querying the time server as a power of 2 in seconds.
So, for the example above, where the time server is ntp.example.com,
the minimum interval is 2 to the power of 12 or 4,096 seconds, which is
a little over an hour (1.14 hours). The minimum interval defaults to 6,
which equates to 2 to the power of 6, which is 64 seconds. The maximum
interval defaults to 10, i.e. 2 raised to the power 10, which is 1,024
seconds. The upper limit for the value is 17, which is 36.4 hours. A
secondary time server is also shown in the example above. The secondary
time server could be used when the primary one is unavailable.
[/os/os-x]
permanent link
Wed, Mar 26, 2014 9:21 pm
Green border around Google Sheets cell
If a green border appears unexpectedly around a cell in a Google Sheets
spreadsheet, then the worksheet is likely open elsewhere. If you've shared
the spreadsheet, someone with whom you have shared it may have it open or
you may have it open on another system or even in another tab within your
browser. In that case the cell that is currently selected in the other
open instance of the worksheet will be highlighted by a green border.
At the top of the worksheet you will also see the number of other instances
of the open worksheet. If it is open in just one other place you will see "1
other viewer" at the top right of the worksheet next to a green square.

If you move the cursor over the cell with the green border, you will
see the name of the other user displayed, or your own logged in name, if you
have the worksheet open multiple times. You can also put the cursor over
the green squares at the top right area above the spreadsheet to see those
names. If the worksheet was open more than twice, e.g., if it was open
3 times, you would see additional green boxes corresponding to the number
of other open instances of it.

[/network/web/services/google]
permanent link
Tue, Mar 25, 2014 9:13 pm
Not enough free disk space for Entourage
If Entourage display the message "Your hard disk is full. The Entrourage
database requires additional free space. Entourage will now quit so you
can make more space available on your hard disk by moving or deleting
files.", if you store a lot of email one area where you may be able to
free disk space is in old identities or backups for an identity beneath
~/Documents/Microsoft User Data
[More Info ]
[/os/os-x/software/office]
permanent link
Mon, Mar 24, 2014 8:17 am
Attempted SQL injection attack
When I checked the webserver's error log file this morning, I noticed
the following two entries related to the IP address 221.11.108.10:
[Mon Mar 24 08:15:07 2014] [error] [client 221.11.108.10] File does not exist: /
home/jdoe/public_html/ctscms
[Mon Mar 24 08:15:12 2014] [error] [client 221.11.108.10] File does not exist: /home/jdoe/public_html/plus, referer: http://support.moonpoint.com/plus/search.php?keyword=as&typeArr[111%3D@`\\'`)+and+(SELECT+1+FROM+(select+count(*),concat(floor(rand(0)*2),(substring((select+CONCAT(0x7c,userid,0x7c,pwd)+from+`%23@__admin`+limit+0,1),1,62)))a+from+information_schema.tables+group+by+a)b)%23@`\\'`+]=a
There is no ctscms file nor directory, nor do I use a search.php file, nor
even have a directory named plus on this web site, so the queries seemed
suspicious.
Performing a Google search on the attempted query to search.php, which
appears to be an SQL query, I
found links to a number of sites in the Chinese language. E.g.,
dedecms plus / search.php latest injection vulnerability (translated
to English).
The query I saw in the Apache error log appeared to be an
SQL injection
attack. In
Arrays in requests, PHP and DedeCMS, an InfoSec Handlers Diary Blog entry,
I found the following in relation to an SQL injection attack used against
/plus/download.php, which is a PHP script associated
with the DedeCMS
Content
Management System (CMS):
And this definitely looks malicious. After a bit of research, it turned
out that this is an attack against a known vulnerability in the DedeCMS,
a CMS written in PHP that appears to be popular in Asia. This CMS has
a pretty nasty SQL injection vulnerability that can be exploited with
the request shown above.
So I blocked any further access to the server hosting this
site from that IP address using a route reject command.
# route add 221.11.108.10 reject
[root@frostdragon ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
221.11.108.10 - 255.255.255.255 !H 0 - 0 -
171.216.29.9 - 255.255.255.255 !H 0 - 0 -
The 221.11.108.10 IP address
is allocated to an entity in China. I blocked another Chinese IP address,
171.216.29.9 two days ago.
The
Arrays in requests, PHP and DedeCMS blog entry indicated the
attacker discussed in that article was using a script that identified itself
with a
user agent string
of
WinHttp.WinHttpRequest:
Additionally, as you can see in the log at the top, the User Agent string
has been set to WinHttp.WinHttpRequest, which indicates that this request
was created by a script or an attack tool executed on a Windows machine.
When I checked the Apache CustomLog to see what user agent string was
submitted with the queries to this site, I saw it was "Googlebot/2.1", so
the attacker appears to be using an updated script.
that misidentifies itself as
Googlebot. The Internet Storm Center blog entry was posted 6 months
ago and discusses a log entry from September 5, 2013. The log entry posted
in that article shows a source IP address of 10.10.10.10, which is a
private IP address
substituted in the article for the actual IP address from
which the attack originated.
I saw the following in my log:
221.11.108.10 - - [24/Mar/2014:08:15:07 -0400] "GET /ctscms/ HTTP/1.1" 404 291 "
-" "Googlebot/2.1 (+http://www.google.com/bot.html)"
221.11.108.10 - - [24/Mar/2014:08:15:12 -0400] "GET /plus/search.php?keyword=as&
typeArr[111%3D@`\\'`)+and+(SELECT+1+FROM+(select+count(*),concat(floor(rand(0)*2
),(substring((select+CONCAT(0x7c,userid,0x7c,pwd)+from+`%23@__admin`+limit+0,1),
1,62)))a+from+information_schema.tables+group+by+a)b)%23@`\\'`+]=a HTTP/1.1" 404
299 "http://support.moonpoint.com/plus/search.php?keyword=as&typeArr[111%3D@`\\
'`)+and+(SELECT+1+FROM+(select+count(*),concat(floor(rand(0)*2),(substring((sele
ct+CONCAT(0x7c,userid,0x7c,pwd)+from+`%23@__admin`+limit+0,1),1,62)))a+from+info
rmation_schema.tables+group+by+a)b)%23@`\\'`+]=a" "Googlebot/2.1 (+http://www.go
ogle.com/bot.html)Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, a
pplication/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-power
point, application/msword, */*"
References:
-
Stopping an Attacker with the Route Reject Command
MoonPoint Support
Date: April 15, 2007
-
Arrays in requests, PHP and DedeCMS
Internet Storm Center
By: Bojan, ISC Handler
[/security/attacks]
permanent link
Sun, Mar 23, 2014 2:08 pm
Julian date in spreadsheets
The
ordinal date, i.e., the day of the year, is a number that ranges from 1 for January 1 through 365
or 366 for December 31, depending if the year is a
leap year.
The ordinal date is also referred to as the
"
Julian date", though
in astronomy "Julian date" is not the ordinal date, but
a serial date system starting on January 1, 4713 B.C.E.
If you wish to display the current ordinal date in a spreadsheet, such as a Microsoft Excel or a
Google Sheets worksheet you can use the formula below:
=TEXT(TODAY() ,"yyyy")&TEXT((TODAY() -DATEVALUE("1/1/"&TEXT(TODAY(),"yy"))+1),"000")
That formula will insert the current day in Julian format with a four-digit
year. E.g. for March 23, 2014, it would result in 2014082
appearing in the cell where the forumla is used, since March 23, 2014 is
the 82nd day of 2014. If you just wish to display
the day of the year and not the year, you can use the formula below:
=TEXT((TODAY() -DATEVALUE("1/1/"&TEXT(TODAY(),"yy"))+1),"000")
That forumula will display 082 in the cell in which the
formula is used.
References:
-
Insert Julian dates
Support - Office.com
[/os/windows/office/excel]
permanent link
Sun, Mar 23, 2014 1:31 pm
W3C Validation
The
World Wide Web Consortium
(W3C) is an international standards organization for the
World Wide Web (WWW).
Among the services offered by the W3C are a
Markup Validation Service a
Link Checker,
a
CSS Validation Service,
and
RSS Feed Validation Service.
The services are free.
The markup
validation service allows you to submit a
URL for a webpage to be
checked by the service or to upload an HTML file to be checked for
incorrect HTML code. If the code in a webpage is incorrect, you may not
see the results you expect for the webpage when it is displayed in a browser
or it may display incorrectly in some browsers used by visitors to the page.
The W3C tool will notify you of the types of errors on the page and the
line numbers on which they are found. You can match those lines numbers with
the appropriate lines in the code in browsers that allow you to view the
source code of a page.
You can provide a URL to the link checker tool and it will determine if any
of the links on the webpage are invalid.
The CSS validation service allows you to check the validity of
Cascading Style Sheets (CSS)
used on webpages to control the appearance and formatting of the pages.
You can provide a URL for a CSS or upload a CSS file to be verified.
The W3C Feed Validation Service
will check the syntax of Atom
or RSS feeds. E.g., if
you use RSS to publish updated information on blog entries, you can provide
the URL for the index.rss file on your site.
The W3C provides other tools as well at
Quality Assurance Tools.
All of the software developed at the W3C is Open Source / Free software, which
means that you can use the software for free and download the code, if you wish.
You can also modify the code to suit your own purposes, if you wish.
There is also a paid W3C Validator
Suite™, if you wish to have the W3C validate an entire site
automatically rather than you validating pages individually.
Note: the W3C validation services can't check pages that require authentication,
but can only check pages that are accessible from the Internet without
passwords or files that you upload to be checked.
[/network/web/design]
permanent link
Sat, Mar 22, 2014 10:49 pm
Blocking Internet access except for virus scanning sites
After a system became infected with malware, I disconnected its network
cable then added rules to the firewall separating it from the Internet
to block all Internet access except for
DNS access to its designated
DNS server provided by the user's
ISP. I then granted
access to the
VirusTotal
IP addresses on all ports. VirusTotal is a website belonging to Google
that will allow you to scan files you upload to it with multiple antivirus
programs to determine if they may be malware.
| Name | IP Addresses |
|---|
| virustotal.com |
216.239.32.21
216.239.34.21
216.239.36.21
216.239.38.21
|
| www.virustotal.com |
74.125.34.46 |
After implementing the firewall rules, I reconnected the network cable
to the system.
Since accessing http://virustotal.com
redirects one to
http://www.virustotal.com, I wasn't able to access the VirusTotal website
until I added the IP address 74.125.34.4 to the list of destination
IP addresses the infected system was allowed to access through the
firewall. Even though I could then access the site's webapge and select
a file to upload, I was unable to actually upload a file that I wanted
to check for malware.
So I then added the IP address for the
Jotti's malware scan website to the
permitted outbound access list for the infected system. I was able to
access it with a web browser on the system and upload a suspect file to
have it scanned by the 22 antivirus programs the site currently uses
to scan uploaded files.
| Name | IP Addresses |
|---|
| virusscan.jotti.org |
209.160.72.83 |
[/security/scans]
permanent link
Sat, Mar 22, 2014 5:42 pm
Blocking access from 171.216.29.98
I noticed entries in Apache's error log today associated with IP address
171.216.29.98:
[Sat Mar 22 15:23:58 2014] [error] [client 171.216.29.98] PHP Notice: Undefined index: HTTP_USER_AGENT in /home/jdoe/public_html/index.php on line 39
[Sat Mar 22 15:23:58 2014] [error] [client 171.216.29.98] PHP Notice: Undefined index: HTTP_USER_AGENT in /home/jdoe/public_html/index.php on line 46
[Sat Mar 22 15:23:58 2014] [error] [client 171.216.29.98] attempt to invoke directory as script: /home/jdoe/public_html/blog/
The error was occurring because of PHP code in the file that checks the
value for
HTTP_USER_AGENT.
I found that the IP address, which is allocated to a system in China, is
listed at the Stop Forum Spam site
as being associated with someone trying to post spam into forums today - see
171.216.29.98.
And when I checked Apache's CustomLog to check the
user agent for the
browser the user or software program running at the site might be using to
identify itself, I found that the log entries indicated that it wasn't
providing user agent information, which browsers and web crawlers normally
provide. The log also showed that other than that one file at the
site's document root, the user or program accessing the site only
queried a directory that has "forums" as part of the path. I have
blog entries posted on forum software, so that may have prompted the
visit to the site from that IP address, if the person or program is
looking for sites where he or it can post forum spam.
I checked the "reputation" of the IP address at other sites that provide
information on whether an IP address has been noted to be associated with
malicous activity and found the following:
-
Site: WatchGuard
Reputation Authority
Rating: Bad
Reputation Score: 95/100
Comment: The score indicates the overall ReputationAuthority reputation
score, including the name and location of the ISP (Internet Service
Provier), for the specified address. A score of 0-50 indicates a good
to neutral reputation. 51-100 indicates that threats have been detected
recently from the address and the reputation has been degraded.
-
Site:
Barracuda Reputation
Reputation: Poor
Comment:
-
Site: McAfee Trusted Source
Reputation: Unrated
Comment:
-
Site:
Check Your IP Reputation - Miracare of Mirapoint
Reputation: High Risk
Comment: This IP address is used for sending Spam on a regular basis
-
Site:
BrightCloud Security Services URL/IP Lookup
Reputation: High Risk
Comment: Location - Chengdu, China. Spam Sources found. Webroot IP Reputation
is listed as "High Risk", but lower down on the page the status assigned
to the address is "Moderate Risk".
To stop any futher access to the server from that IP address, from the
root account, I used the route command to reject access by the IP address.
# route add 171.216.29.9 reject
Note: the command is valid on a Linux system, but though the route
command is available on a Microsoft Windows system, that operating system
doesn't support the "reject" parameter.
The blocked route can be seen by issuing the route command with no
parameters.
# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
171.216.29.9 - 255.255.255.255 !H 0 - 0 -
If I ever want to permit access to the server from that IP address again,
I could use route del 171.216.29.9 to permit access from that
address.
References:
-
Stopping an Attacker with the Route Reject Command
MoonPoint Support
Date: April 15, 2007
[/security/scans]
permanent link
Sat, Mar 22, 2014 2:10 pm
Renamed Website Files Still Being Crawled
I've noticed in the site's error logs that files that haven't existed on
the site for years are producing error entries when
web crawers still
attempt to access them. Apparently, elsewhere on the web that are still
links pointing to the nonexistent files, which has led me to conclude that
I need to create redirects for those files on the site that I move or rename,
if the files have been on the site for any significant lengthh of time.
[ More Info ]
[/network/web/crawlers]
permanent link
Fri, Mar 21, 2014 9:55 pm
Favicon.ico
While trying to reduce entries in the site's Apache error log, I've
decided I should eliminate the many "File does not exist" error messages
for
favicon.ico. I often see attempts to access that file
from the site's root directory, but, since there is no such file, a lot
of extraneous entries appear in the error log file for it when browsers
attempt to access it.
Favicon is short for
"favorite icon" and is also known as a "shortcut icon". Favicons were first
supported in March 1999 when Microsoft released
Internet Explorer
5. In December of 1999, the
World Wide
Web Consortium (W3C) made it a standard element in HTML 4.01
recommendation to be used with a
link relation in
the
<head> section of an HTML document. It is now widely supported
among browsers.
The original purpose of a favicon was to provide a small icon, commonly
16 x 16 pixels, that a browser would associate with a website when a user
bookmarked the site. Today, browsers typically display a page's favicon
in their address bar and
sometimes also in the browser's history display as well as using it in
association with a bookmark. Those browsers that provide a
tabbed
document interface (TDI) also typically display the favicon next to
a page's title on a tab for the site with which the favicon is associated.
I had an icon I had used years ago, but decided I liked
the crescent
moon icon, I found at favicon.cc
better. That site provides a tool that will allow you to create your
own favicon. It also provides many free icons that you can download.
To use the icon file, you can simply place the favicon.ico
in the root directory of the website where browsers can automatically locate
it. Or you can place it elsewhere on the site and specify its location
by inserting the following code within the head section of the HTML code
for a page, substituing the relative path from the website's document
root for YOUR_PATH.
<link href="/YOUR_PATH/favicon.ico" rel="icon" type="image/x-icon" />
Something like the following is also acceptable. I.e., in addition to
specifying the file's location you can can also give the file a name
other than favicon.ico.
<link rel="icon" href="http://example.com/myicon.ico" />
The file also does not have to be a .ico file. See the
file format
support section of the Wikipedia
Favicon article
for other image file formats that are supported by various browsers.
[/network/web/browser]
permanent link
Thu, Mar 20, 2014 9:21 pm
Check marks, x marks, and checkboxes
If you need to represent a
check mark,
aka tick mark, or an
x
mark, aka cross, x, ex, exmark, and into mark, or a
checkbox, aka check box,
tick box, and ballot box, which someone can checkmark, on a webpage, there
are a number of HTML codes that can be used to do so. The codes can be
represented in
decimal
or
hexadecimal
format depending on your personal preference.
| | | Code |
|---|
| Symbol | Description | Decimal | Hexadecimal |
|---|
| ☐ | ballot box | ☐ | ☐ |
| ☑ | ballot box with check | ☑ | ☑ |
| ☒ | ballot box with x | ☒ | ☒ |
| ✅ | white heavy check mark | ✅ | ✅ |
| ✓ | check mark | ✓ | ✓ |
| ✔ | heavy check mark | ✔ | ✔ |
| × | mulitplication sign | × | × |
| ✕ | large multiplication sign | ✕ | ✕ |
| ✖ | heavy multiplication sign | ✖ | ✖ |
| ⨯ | cross product, also known as Gibb's vector
product | ⨯ | ⨯ |
| ✗ | ballot x | ✗ | ✗ |
| ✘ | heavy ballot x | ✘ | ✘ |
If you see squares or question marks instead of the symbols, you may need an appropriate language pack installed to display the symbols.
[/network/web/html]
permanent link
Wed, Mar 19, 2014 11:17 pm
AuthUserFile not allowed here
After setting up a redirect similar to the following in an .htaccess file in
a directory, I found that I would get a
500 Internal Server Error
with the message "The server encountered an internal error or
misconfiguration and was unable to complete your request." whenever I tried
to access a file in a password-protected subdirectory beneath the one
in which I had created the .htaccess file to have the Apache server
redirect visitors accessing an old .html file that I had replaced with a
.php one.
Redirect 301 /dir1/dir2/example.html /dir1/dir2/example.php
In the Apache error log for the website, I saw the following:
[Wed Mar 19 21:05:17 2014] [alert] [client 192.168.0.10] /home/jdoe/public_html/dir1/dir2/dir3/.htaccess: AuthUserFile not allowed here, referer: http://support.moonpoint.com/dir1/dir2/example.php
That error log entry was created when I clicked on a link I had
in example.php to access a file in the directory dir3, which was below the
one in which example.php was located.
To allow the redirect to work, I had inserted the following code in
the VirtualHost section for the website within Apache's
/etc/httpd/conf/httpd.conf file.
<Directory /home/jdoe/public_html/dir1/dir2>
AllowOverride FileInfo
</Directory>
The .htaccess file for controlling access to the subdirectory
dir1/dir2/dir3 had worked fine until I created another
.htaccess file above it in dir2 for the redirect. The one for controlling access
to dir3 with a username and password was similar to the following:
AuthUserFile /home/jdoe/public_html/.htpasswd-test
AuthGroupFile /dev/null
AuthName Testing
AuthType Basic
Require user test1
Because it contained AuthUserFile and
AuthGroupFile, but I didn't specify AuthConfig
within the <Directory> section for the virtual host
in the httpd.conf file, but only FileInfo
for AllowOverride, the authorization control no longer
worked. When I changed the AllowOverride line to that
shown below and restarted Apache with apachectl restart
then both the redirect for the file in dir2 and the HTTP
basic access
authentication method for files in the subdirectory dir3
beneath dir2 both worked.
<Directory /home/jdoe/public_html/dir1/dir2>
AllowOverride AuthConfig FileInfo
</Directory>
I had forgotten that by limiting AllowOverride to just
FileInfo for dir2, I was effectively nullifying any other
type of overrides in any subdirectores beneath it.
References:
-
Apache Core Feartures
Apache HTTP Server Project
[/network/web/server/apache]
permanent link
Tue, Mar 18, 2014 10:34 pm
Use netsh to determine WLAN driver version
To obtain information about the driver for the wirless interface in a
Microsoft Windows system, the
netsh command may be used.
After issuing the command from a command prompt, you can type
wlan,
then
show drivers to show the properites of the wireless
LAN drivers on the system.
C:\Users\JDoe>netsh
netsh>wlan
netsh wlan>show drivers
Interface name: Wi-Fi
Driver : Realtek RTL8188E Wireless LAN 802.11n PCI-E NIC
Vendor : Realtek Semiconductor Corp.
Provider : Realtek Semiconductor Corp.
Date : 2/27/2013
Version : 2007.10.227.2013
INF file : C:\windows\INF\oem13.inf
Files : 2 total
C:\windows\system32\DRIVERS\rtwlane.sys
C:\windows\system32\drivers\vwifibus.sys
Type : Native Wi-Fi Driver
Radio types supported : 802.11n 802.11b 802.11g
FIPS 140-2 mode supported : No
802.11w Management Frame Protection supported : Yes
Hosted network supported : Yes
Authentication and cipher supported in infrastructure mode:
Open None
WPA2-Personal CCMP
Open WEP-40bit
Open WEP-104bit
Open WEP
WPA-Enterprise TKIP
WPA-Personal TKIP
WPA2-Enterprise TKIP
WPA2-Personal TKIP
WPA-Enterprise CCMP
WPA-Personal CCMP
WPA2-Enterprise CCMP
Vendor defined TKIP
Vendor defined CCMP
Vendor defined Vendor defined
Vendor defined Vendor defined
WPA2-Enterprise Vendor defined
WPA2-Enterprise Vendor defined
Vendor defined Vendor defined
Vendor defined Vendor defined
Authentication and cipher supported in ad-hoc mode:
Open None
Open WEP-40bit
Open WEP-104bit
Open WEP
WPA2-Personal CCMP
IHV service present : Yes
IHV adapter OUI : [00 e0 4c], type: [00]
IHV extensibility DLL path: C:\windows\system32\Rtlihvs.dll
IHV UI extensibility ClSID: {6c2a8cca-b2a2-4d81-a3b2-4e15f445c312}
IHV diagnostics CLSID : {00000000-0000-0000-0000-000000000000}
netsh wlan>Or you can issue the netsh wlan show drivers command
at the command prompt to have the information shown and be immediately
returned to the command prompt.
[/os/windows/commands]
permanent link
Mon, Mar 17, 2014 5:48 pm
Recursively locating HTML files
To recursively locate files of a particular file type, e.g., HTML files, on
a Unix, Linux, or OS X system from a command line interface, aka shell prompt,
the following command can be used:
find . -name "*.html"
The subdirectory path will be included in the output along with the file names.
If you wish to have a count of the number of such files, you can use
either of the two commands below:
find . -name "*.html" | grep -c .
find . -name "*.html" | wc -l
Note: if you use the grep command, be sure to include the dot after the
-c.
[/os/unix/commands]
permanent link
Mon, Mar 17, 2014 5:30 pm
How to have Firefox forget basic access authentication credentials
If you've accessed a webpage that uses HTTP
basic access authentication to prompt for a user name and password
to control access to a web page within Firefox, you can have Firefox
"forget" those credentials so you can enter different ones by the
following two methods.
Method 1
Note: this method applies for Firefox 27 and may not apply
to all other versions.
-
Click on Firefox at the upper, left-hand corner of the Firefox window
to access its menu.

-
Select History.
-
Select Clear Recent History.
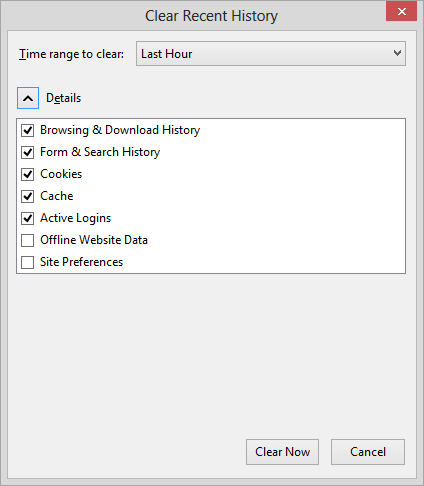
-
If the site was accessed within the last hour, you can leave "time range to
clear" set at "Last Hour"; if not, you may need to change the value to a
longer period. With Details visible, you can clear the checkmarks for
all the items, except Active Logins, if you wish.
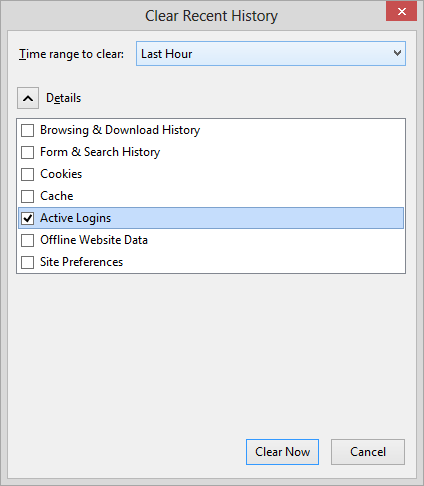
-
Click on the Clear Now button.
Method 2
Note: This method may work for some other browsers as well as Firefox, but
won't work for Internet Explorer. An advantage to this method is it
is applied to just the particular website. It doesn't cause Firefox
to forget the credentials for any other websites.
With some browsers, you can specify the credentials to use to access
a webpage protected by basic authenticaion by putting the userid and
password in the URL for the page with
http://user:pass@www.example.com, substituting
a username for the site for "user" and a password that goes
with that username for "pass" in the address line, e.g.
http://bob:mypassword@www.example.com.
If you put http://abc@www.example.com/some-page.html in the
address bar for the webpage some-page.html that is protected
by the basic authentication method, then the browser can be caused to
forget a valid set of credentials previously used to access that page that
Firefox remembers and will normally reuse until you exit from Firefox. You
will be prompted by the website for a new set of valid credentials,
allowing you to enter a new user name and passwrod to access the page
or cause your browser to forget the previously valid ones.
[/network/web/browser/firefox]
permanent link
Sun, Mar 16, 2014 11:59 am
List of accounts on a Linux or Unix system
To see a list of accounts on a Linux or Unix system, the following command
can be used:
cut -d: -f1 /etc/passwd
[/os/unix/commands]
permanent link
Sun, Mar 16, 2014 9:41 am
Determining low, high, average, and median values with Google Sheets
To determine the smallest, largest, average, and median value for a column
of numbers in a
Google Sheets spreadsheet, the
MIN,
MAX,
AVERAGE, and
MEDIAN functions can be used.
For a column of numbers from A2 to A66, the following forumlas could
be used:
| Minimum: | MIN(A2:A66) |
| Maximum: | MAX(A2:A66) |
| Average: | AVERAGE(A2:A66) |
| Median: | MEDIAN(A2:A66) |
[/network/web/services/google]
permanent link
Sat, Mar 15, 2014 11:17 am
Changing the Channel Number on a NetGear CVG824G Router
Sometimes wireless network disconnections and slow data transfers can
be caused by interference between multiple
wireless access
points, such as neighboring wireless routers using the same radio
frequency channel for communications. Simply changing the channel number
used for wireless communications by one of the routers may resolve the problem.
For a NETGEAR® Wireless Cable Voice Gateway Model CVG824G device,
the channel number can be changed using
these steps.
[/hardware/network/router/netgear]
permanent link
Fri, Mar 14, 2014 10:30 pm
Excel countifs function
Microsoft Excel, starting with Excel 2007, provides a function,
countifs, to count the number of occurrences of some item while
stipulating multiple criteria be met. The function also is available in
Microsoft® Excel® 2008 for Mac. The function works like the
countif function, but whereas
countif only permits one
criteria to be stipulated,
countifs supports one or
more criteria. The syntax for
countifs is:
COUNTIFS( criteria_range1, criteria1, [criteria_range2, criteria2, ...
criteria_range_n, criteria_n] )
As an example, suppose I have the following worksheet in a spreadsheet:
| <> |
A |
B |
C |
D |
| 1 |
Number | Project | Approved | Funded |
| 2 | 38397 | Alpha | 2/12/14 | N |
| 3 | 38400 | Alpha | 2/7/14 | Y |
| 4 | 38407 | Beta | 3/4/14 | N |
| 5 | 38408 | Alpha | 2/25/14 | N |
| 6 | 38409 | Epsilon | 3/14/14 | Y |
| 7 | 38412 | Gamma | 3/14/14 | Y |
| 8 | 38413 | Zeta | 3/14/14 | Y |
| 9 | 38415 | Alpha | 3/14/14 | N |
| 10 | | | | |
| 11 |
Approved today |
4 |
| |
| 12 |
Approved and funded today |
3 |
| |
Number represents work request numbers associated with various projects.
Column C has dates for when the work requests were approved with today's
date being March 14, 2014. Column D indicates whether the requests have
been funded with a "Y" for "yes" and a "N" for "no".
If I wished to count the number of work requests funded today, I
could use the formula =COUNTIF(C2:C10,TODAY()) in cell B11.
COUNTIF works because I have only one criteria. But, if I wanted
to count the number that were approved and funded today, then I
would need to use COUNTIFS rather than COUNTIF. I could use the
formula =COUNTIFS(C2:C10,TODAY(),D2:D10,"Y") in
cell B12.
[/os/windows/office/excel]
permanent link
Fri, Mar 14, 2014 9:55 am
Netsh command to show available Wi-Fi networks
On a system running Microsoft Windows, you can see the available Wi-Fi
networks near the system,the signal strengths, channel numbers, etc.
for each from a
command prompt using the command
netsh show
networks mode=Bssid
C:\Users\JDoe>netsh
netsh>wlan
netsh wlan>show networks mode=Bssid
Interface name : Wi-Fi
There are 5 networks currently visible.
SSID 1 : 558935
Network type : Infrastructure
Authentication : WPA2-Personal
Encryption : CCMP
BSSID 1 : 0c:54:a5:48:19:e5
Signal : 81%
Radio type : 802.11n
Channel : 1
Basic rates (Mbps) : 1 2 5.5 11
Other rates (Mbps) : 6 9 12 18 24 36 48 54
SSID 2 : Haze
Network type : Infrastructure
Authentication : WPA2-Personal
Encryption : CCMP
BSSID 1 : 94:44:52:5a:54:54
Signal : 83%
Radio type : 802.11n
Channel : 11
Basic rates (Mbps) : 1 2 5.5 11
Other rates (Mbps) : 6 9 12 18 24 36 48 54
SSID 3 : 08FX02038916
Network type : Infrastructure
Authentication : Open
Encryption : WEP
BSSID 1 : 00:18:3a:8a:01:c5
Signal : 49%
Radio type : 802.11g
Channel : 6
Basic rates (Mbps) : 1 2 5.5 11
Other rates (Mbps) : 6 9 12 18 24 36 48 54
SSID 4 : linksys
Network type : Infrastructure
Authentication : Open
Encryption : None
BSSID 1 : 00:13:10:fa:ef:a3
Signal : 45%
Radio type : 802.11g
Channel : 6
Basic rates (Mbps) : 1 2 5.5 11
Other rates (Mbps) : 6 9 12 18 24 36 48 54
SSID 5 : Hickox
Network type : Infrastructure
Authentication : Open
Encryption : WEP
BSSID 1 : 0c:d5:02:c5:e8:8c
Signal : 48%
Radio type : 802.11g
Channel : 11
Basic rates (Mbps) : 1 2 5.5 11
Other rates (Mbps) : 6 9 12 18 24 36 48 54
netsh wlan>
[/os/windows/commands]
permanent link
Thu, Mar 13, 2014 11:15 pm
Netsh show interfaces
The signal strength for wireless network connectivity can be checked
on a Windows system from the command line using the
netsh
command. From a command prompt issue the command
netsh
and when the netsh prompt appears issue the command
wlan
and then
show interfaces.
C:\Users\JDoe>netsh
netsh>wlan
netsh wlan>show interfaces
There is 1 interface on the system:
Name : Wi-Fi
Description : Realtek RTL8188E Wireless LAN 802.11n PCI-E NIC
GUID : d79cd37a-fe78-482b-b23e-af4953ba9f6b
Physical address : 48:d2:24:68:e1:aa
State : connected
SSID : Haze
BSSID : 94:44:52:5a:54:54
Network type : Infrastructure
Radio type : 802.11n
Authentication : WPA2-Personal
Cipher : CCMP
Connection mode : Auto Connect
Channel : 11
Receive rate (Mbps) : 72
Transmit rate (Mbps) : 72
Signal : 100%
Profile : Haze
Hosted network status : Not available
netsh wlan>The signal strength for the wireless connection is shown on the
Signal line, e.g., 100% in the case above. The wireless
connection is using the 802.11n
wireless network standard, which is one of the
802.11 standards.
[/os/windows/commands]
permanent link
Wed, Mar 12, 2014 11:40 pm
Adding "rel=nofollow" to Blosxom advanced search option for find plugin
I've noticed in the logs for the blog that search engines are trying to
access pages with "?advanced_search=1" in the URL. E.g., I've seen a lot
of entries similar to the following:
5.10.83.52 - - [12/Mar/2014:00:32:23 -0400] "GET /blog/blosxom/<a%20href=/<a%20h
ref=/<a%20href=/2008/05/01/2008/03/2008/05/05/network/email/clients/outlook/2008
/10/network/email/sendmail/2008/07/network/email/clients/outlook/2008/05/25/2008
/12/2008/05/18/2008/05/03/index.html?advanced_search=1 HTTP/1.1" 200 12080 "-" "
Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)"
They seem to be getting erroneous URLs reflecting a directory structure
related to dates that doesn't exist on the system. The URLs appear to be
related to the find plugin, since its search option includes code for
"advanced_search=1", so I've edited the Perl code for that plugin to
include rel="nofollow" at the end of the URL generated for
the advanced search capability.
The orignal code was:
<a href="$blosxom::url/$path_withflavour?advanced_search=1">Advanced Search</a>
The line is now:
<a href="$blosxom::url/$path_withflavour?advanced_search=1" rel="nofollow">Advanced Search</a>
Adding rel="nofollow" to a URL tells search engines, such as
Google's search engine not to follow any link that includes the nofollow
parameter.
The following meta tag can be included in the head section of the HTML code
for a page to tell search engines not to follow any links on a page.
<meta name="robots" content="nofollow">
But there may be instances, such as this case for me, where a webpage
designer wants only some links on a page not to be followed to their
destination by search engines.
The attribute can also be added to individual links if you don't want
to vouch for the content of the page to which the link points. E.g., adding
it to links placed in comments by those commenting on a page will allow
visitors to go to the linked page, but search engines that adhere to the
nofollow parameter won't use the link to increase their ranking of the page
to which the link points, which may discourage some comment spammers.
The rel="nofollow" option for links was developed as a
way to combat link
spam. In January 2005, Google, Yahoo! and MSN announced that they would
support use of the "nofollow" tag as a way to deter link spam. Microsoft's
MSN Spaces and
Google's Blogger
blogging services joined the effort to utilize the tag to discourage
link spamming At that time a number of blog software providers, including
Six Apart,
WordPress,
Blosxom, and blojsom, also
joined the effort by supporting use of the tag.
References:
-
Use rel="nofollow" for specific links
Google Webmaster Tools
-
Wipedia ponders joining search engines in fight against spam
By: Michael Snow
Date: January 24, 2005
[/network/web/blogging/blosxom]
permanent link
Tue, Mar 11, 2014 10:31 pm
Determining resolution from the command line on OS X
To determine the video resolution from a command line, such as a
Terminal shell prompt, on an OS X system, you can use the command
system_profiler SPDisplaysDataType.
$ system_profiler SPDisplaysDataType
Graphics/Displays:
NVIDIA GeForce 9400M:
Chipset Model: NVIDIA GeForce 9400M
Type: GPU
Bus: PCI
VRAM (Total): 256 MB
Vendor: NVIDIA (0x10de)
Device ID: 0x0863
Revision ID: 0x00b1
ROM Revision: 3448
gMux Version: 1.8.8
Displays:
Color LCD:
Display Type: LCD
Resolution: 1440 x 900
Pixel Depth: 32-Bit Color (ARGB8888)
Main Display: Yes
Mirror: Off
Online: Yes
Built-In: Yes
NVIDIA GeForce 9600M GT:
Chipset Model: NVIDIA GeForce 9600M GT
Type: GPU
Bus: PCIe
PCIe Lane Width: x16
VRAM (Total): 512 MB
Vendor: NVIDIA (0x10de)
Device ID: 0x0647
Revision ID: 0x00a1
ROM Revision: 3448
gMux Version: 1.8.8In the example above, the video resolution for the MacBook Pro
on which I ran the command is 1440 x 900. The
Screen Information page
at BrowserSpy.dk will also report
a system's screen resolution, if you visit that page using a browser on
the system. In this case it reports a width of 1440 and a height of 900 pixels
for the MacBook Pro.
[/os/os-x]
permanent link
Mon, Mar 10, 2014 10:29 pm
Debug output for calendar plugin for Blosxom
I've been using
Blosxom for
this blog and version 0+6i of the
calendar
plugin for Blosxom written by Todd Larason whose website seems
to no longer be extant, though it is available through the
Internet Archive's
WayBack Machine
here.
The last time the Internet Archive archived the site was on March
25, 2010. The plugin can be downloaded from this site at
Calendar Plugin for Blosxom.
The plugin has been contributing a lot of entries in the
site's error log that appear to be related to normal behavior for the
plugin. I've been ignoring them, since the plugin has been working fine
and the entries seem to be more informatonal in nature than reflective
of a problem with the plugin. E.g., I see a lot of entries similar to
the following:
[Sun Mar 09 23:59:19 2014] [error] [client 10.0.90.23] calendar debug 1: start() called, enabled
[Sun Mar 09 23:59:20 2014] [error] [client 10.0.90.23] calendar debug 1: filter() called
[Sun Mar 09 23:59:20 2014] [error] [client 10.0.90.23] calendar debug 1: Using cached state
[Sun Mar 09 23:59:20 2014] [error] [client 10.0.90.23] calendar debug 1: head() called
[Sun Mar 09 23:59:20 2014] [error] [client 10.0.90.23] calendar debug 1: head() done, length($month_calendar, $year_calendar, $calendar) = 3947 1212 5229
I finally decided I should stop the production of those entries, though,
so I could more readily see log entries that are significant. So I looked
at the Perl code for the plugin. On line 30, I see the following:
$debug_level = 1 unless defined $debug_level;
The debug surboutine is on lines 49 through 56 and is as follows:
sub debug {
my ($level, @msg) = @_;
if ($debug_level >= $level) {
print STDERR "$package debug $level: @msg\n";
}
1;
}
On line 517, I see the following comment.
C<$debug_level> can be set to a value between 0 and 5; 0 will output
no debug information, while 5 will be very verbose. The default is 1,
and should be changed after you've verified the plugin is working
correctly.
Since the plugin has been working for a long time and I don't need to
see the debugging information, I set the value for debug_level
on line 30 to zero instead of one.
$debug_level = 0 unless defined $debug_level;
That has stopped the insertion of the calendar plugin entries in the
Apache error log file with no effect on the calendar's functionality.
[/network/web/blogging/blosxom]
permanent link
Sun, Mar 09, 2014 4:04 pm
Redirecting a URL on an Apache Web Server
If you are using an Apache webserver and you need to redirect visitors to
a webpage to another webpage, instead, one method of doing so is to use a
server-side redirect, which can be accomplished by inserting a redirect in
an .htaccess file, to the new page.
[ More Info ]
[/network/web/server/apache]
permanent link
Sat, Mar 08, 2014 10:14 pm
Turning off command echo in MUSHclient but retaining command history
For
MUSHclient, if you don't
want commands echoed back to you when you type them, but
want them stored in the command history, leave command echo turned on.
You can check that it is turned on after you connect to the
MUSH by
clicking on
Display. You should not see a check mark next to
No Command Echo. If one is there click on
No Command Echo
to uncheck it.
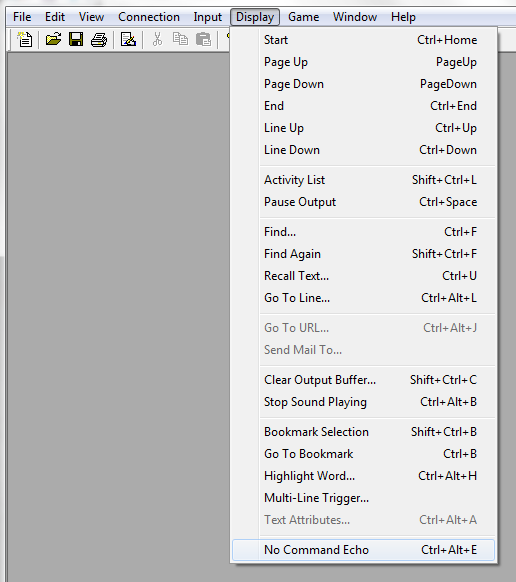
You then need to take the following steps:
- Click on Game.
- Select Configuration.
- Select All Configuration.
- Uncheck the checkbox next to "Echo My Input
In" under Output Window.
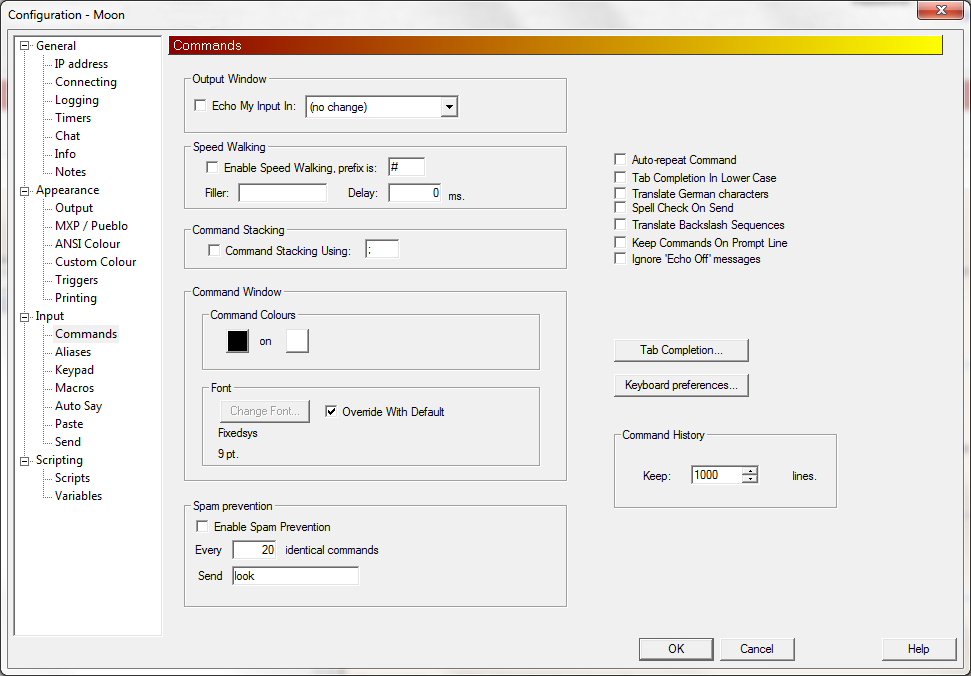
- Make sure the value for the number of lines to keep
under Command History is not set to 0, but is set to the number
of commands you want to keep in the history; the default value is
1,000 lines..
- Click on OK.
You should then be able to see commands you type in the command
history window that you can open with Ctrl-H. If you want
to save the setting so that you don't have to change it the next
time you connect to the MUSH, click on File and select
Save World Details.
Instructions appy to version 4.84.
[/gaming/mushclient]
permanent link
Fri, Mar 07, 2014 10:20 pm
Using mdfind to locate files
On a Mac OS X system, you can use the
mdfind command to locate
files on the system from a command line interface, e.g., from a shell prompt
that you may obtain by running the
Terminal program, which is located
in
Applications/Utilities. You can specify the name of the
file using the
-name option.
$ mdfind -name Waterfalls.mp3
/Users/jdoe/Music/iTunes/iTunes Media/Music/Bob Weir/Relax With Soothing Waterfalls/01 Soothing Waterfalls.mp3
/Users/jdoe/Downloads/Waterfalls.mp3
You can specify just part of the file name and the search is not case
specific, i.e., "waterfall" and "Waterfall" are deemed identical.
$ mdfind -name waterfall
/Users/jdoe/Downloads/Waterfalls.mp3
/Users/jdoe/Music/iTunes/iTunes Media/Music/Bob Weir/Relax With Soothing Waterfalls/01 Soothing Waterfalls.mp3
/Users/jdoe/Music/iTunes/iTunes Media/Music/Bob Weir/Relax With Soothing Waterfalls
/Library/Desktop Pictures/Eagle & Waterfall.jpg
As shown in the above example, directories whose names contain the
string
on which you are performing the search, i.e., "waterfall" in the above case,
will also be returned.
If you just want a count of files and directories containing a
particular string, such as "waterfall" in the name, you can add the
-count parameter.
$ mdfind -count -name waterfall
4
If you want to limit the search to a particular directory you can use
the -onlyin parameter.
$ mdfind -name waterfall -onlyin "/Library/Desktop Pictures/"
/Library/Desktop Pictures/Eagle & Waterfall.jpg
[/os/os-x]
permanent link
Thu, Mar 06, 2014 10:43 pm
Using sw_vers to obtain OS X version
On a MAC OS X system, you can obtain information on the operating system
version from a command line interface, e.g. from a terminal session, which
you can get by running the
Terminal program in
Applications/Utilities, by using the
sw_vers command.
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.8.3
BuildVersion: 12D78
If you are only interested in the ProductName, ProductVersion
, or BuildVersion, you can specify arguments that will
restrict the output to just that informaton.
$ sw_vers -productName
Mac OS X
$ sw_vers -productVersion
10.8.3
$ sw_vers -buildVersion
12D78
You can also get the OS X version number using the
system_profiler command.
$ system_profiler SPSoftwareDataType | grep "System Version"
System Version: OS X 10.8.3 (12D78)
[/os/os-x]
permanent link
Wed, Mar 05, 2014 10:38 pm
Audio File Play - afplay
On Mac OS X systems you can play an audio file, such as an MP3 file, from a
command-line
interface, i.e., a shell prompt, which you can get by running the
Terminal program found in
/Applications/Utilities,
by using the audio file play command,
afplay. E.g.:
afplay Waterfalls.mp3
You can terminate the playing of the audio file using Ctrl-C.
You can specify that the audio file only be played for a specific number of
seconds using the -t or --time argument. E.g., the
following command would play the specified MP3 file for 10 seconds and then
terminate afplay:
afplay --time 10 Waterfalls.mp3
For help on the command use afplay -h.
$ afplay -h
Usage:
afplay [option...] audio_file
Options: (may appear before or after arguments)
{-v | --volume} VOLUME
set the volume for playback of the file
{-h | --help}
print help
{ --leaks}
run leaks analysis
{-t | --time} TIME
play for TIME seconds
{-r | --rate} RATE
play at playback rate
{-q | --rQuality} QUALITY
set the quality used for rate-scaled playback (default is 0 - low quality, 1 - high quality)
{-d | --debug}
debug print output
[/os/os-x]
permanent link
Tue, Mar 04, 2014 11:35 pm
Obtaining info on an audio file with afinfo
You can obtain information on an audio file, such as an
MP3 file
on a Mac OS X system from the command line using the
afinfo
command.
$ afinfo Waterfalls.mp3
File: Waterfalls.mp3
File type ID: MPG3
Num Tracks: 1
----
Data format: 2 ch, 44100 Hz, '.mp3' (0x00000000) 0 bits/channel, 0 bytes/packet, 1152 frames/packet, 0 bytes/frame
no channel layout.
estimated duration: 3642.644850 sec
audio bytes: 72852897
audio packets: 139445
bit rate: 160000 bits per second
packet size upper bound: 1052
maximum packet size: 523
audio data file offset: 2228
optimized
audio 160637484 valid frames + 528 priming + 2628 remainder = 160640640
----The command will tell you the
bit
rate and the estimated duration if you choose to play the file. In the
example above, the MP3
bitrate is 160 kbit/s, which is a mid-range bitrate quality for an MP3 file.
Common bitrates for MP3 files are as follows:
- 32 kbit/s – generally acceptable only for speech
- 96 kbit/s – generally used for speech or low-quality streaming
- 128 or 160 kbit/s – mid-range bitrate quality
- 192 kbit/s – a commonly used high-quality bitrate
- 320 kbit/s – highest level supported by MP3 standard
The estimated playing time of the MP3 file in the example above is
3642.644850 sec. You can convert that to minutes from the command line by
passing a command to python to convert seconds to minutes.
$ python -c "print 3642.644850 / 60"
60.7107475
If you wanted to convert that to hours, you could just divide by 60
minutes per hour by adding another "/ 60" at the end of the command.
$ python -c "print 3642.644850 / 60 / 60"
1.01184579167
If you just want to know the bit rate, you can pipe the output of
afinfo through grep and awk:
$ afinfo Waterfalls.mp3 | grep "bit rate" | awk '{print $3}'
160000If you just want to know the duration in seconds, you can use the
following commands:
$ afinfo Waterfalls.mp3 | grep "estimated duration" | awk '{print $3}'
3642.644850If you want the value in minutes you can also use awk to print that value
instead.
$ afinfo Waterfalls.mp3 | grep "estimated duration" | awk '{print $3 / 60 , "minutes"}'
60.7107 minutes
[/os/os-x]
permanent link
Mon, Mar 03, 2014 7:31 pm
YandexBot Web Crawler
When checking my website logs to see if there were any entries indicating it
had been "crawled", i.e., indexed, by
DuckDuckGo, I found that there were no log entries for any of the
IP addresses used by the
DuckDuckGoBot for
indexing webpages
for 2013 nor for 2014. I found at DuckDuckGo's
Sources webpage that
though the search engine has its own
web crawler, it relies
heavily on indexes produced by the web crawlers for other search engines
stating:
DuckDuckGo gets its results from
over one hundred sources, including DuckDuckBot (our own
crawler), crowd-sourced
sites (like Wikipedia, which are stored in our own index),
Yahoo! (through
BOSS), Yandex,
WolframAlpha, and Bing.
DuckDuckGo's page states they apply their own algorithm to rank
results obtained from other search engines upon which they rely for
data.
One of the search engines mentioned was
Yandex.
The Yandex search engine,
Yandex Search, can be accessed at
www.yandex.com. According to the Wikipedia articles for
Yandex
and Yandex Search
the company operates the largest search engine in Russia with about 60%
market share in Russia with its search engine generating 64% of all Russian web
search traffic in 2010. The article on the company also states:
Yandex ranked as the 4th largest search engine worldwide, based on
information from
Comscore.com, with more than 150 million searches per day as of April 2012,
and more than 50.5 million visitors (all company's services) daily as
of February 2013.
The article also indicates Yandex is heavily utilized in Ukraine and Kazakhstan,
providing nearly a 1/3 of all search results in those countries and 43% of all
search results in Belarus.
When I searched the logs for this year for this website, I found quite a
few entries indicating the site had been indexed by the Yandex web crawler.
I.e., there were many entries containing the following:
"Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)"
In the homepage for this site, I include
PHP code to notify me whenever Google's Googlebot indexes the site,
so I updated that code to include a check that will lead to an email alert
being sent to me whenever the YandexBot indicates the site, also.
<?php
$email = "me@example.com";
if( eregi("googlebot", $_SERVER['HTTP_USER_AGENT']) )
{
mail($email, "Googlebot Alert",
"Google just indexed your following page: " .
$_SERVER['REQUEST_URI']);
}
if( eregi("YandexBot", $_SERVER['HTTP_USER_AGENT']) )
{
mail($email, "Yandex Alert",
"Yandex just indexed your following page: " .
$_SERVER['REQUEST_URI']);
}
?>
[/network/web/search]
permanent link
Mon, Mar 03, 2014 5:17 pm
Removing a site from search results
If you don't wish to have any results returned for a particular site when
you are performing a search using
Google,
Bing,
Yahoo, or
DuckDuckGo, you can include the option
-site
on the search line. E.g., if I wished to search for "accessing
deleted wikipedia pages", but didn't want any results returned from
Wikipedia.org, I could use the following
search terms:
accessing deleted wikipedia pages -site:wikipedia.org
If you wish to include only results for a particular site, then you
would put the site's name after the word site, e.g., if
I wished to search just moonpoint.com, I could use the following:
accessing deleted wikipedia pages site:moonpoint.com
If you restrict searches using the site
option, if you use a domain name such as moonpoint.com,
results will also be returned for any domain names that include
the specified domain name at the end of the domain name, e.g.,
in this case anything on www.moonpoint.com or
support.moonpoint.com would also be returned.
The same is true when using the -site option, i.e.,
no results would be returned for en.wikipedia.org
or www.wikipedia.org in the first example.
[/network/web/search]
permanent link
Sun, Mar 02, 2014 10:40 pm
F-Secure Rescue CD 3.16
F-Secure provides a free Rescue CD which allows you to boot a PC from a CD and
scan it for malware using F-Secure's antivirus software. The F-Secure Rescue
CD will attempt to disinfect any infected files and will rename any it can't
disinfect by putting a .virus extension at the end of the file name. By doing
that, when you reboot the system into Microsoft Windows, the infected file will
not be loaded into memory.
[ More Info ]
[/security/antivirus/f-secure]
permanent link
Sun, Mar 02, 2014 10:36 pm
Installing the SSH Server Service on Knoppix
You can determine if a
Knoppix
Linux system is listening for
SSH connections on the
standard SSH
TCP
port of 22 by issuing the command
netstat -a | grep ssh. If you
are returned to the shell prompt with no results displayed, then the
system isn't listening for SSH connections on port 22.
root@Microknoppix:/# netstat -a | grep ssh
root@Microknoppix:/#
You can also check to see if it is running by using the command
service --status-all. If there is a plus sign next to
ssh, it is running. If, instead, there is a minus sign, it is not
running.
root@Microknoppix:/# service --status-all
[ - ] acpid
[ - ] bootlogd
[ - ] bootlogs
[ ? ] bootmisc.sh
[ ? ] checkfs.sh
[ - ] checkroot.sh
[ ? ] console-screen.sh
[ ? ] console-setup
[ ? ] cpufrequtils
[ ? ] cron
[ ? ] cryptdisks
[ ? ] cryptdisks-early
[ + ] dbus
[ + ] ebtables
[ ? ] etc-setserial
[ - ] fsaua
[ ? ] fsrcdtest
[ - ] fsupdate
[ ? ] fsusbstorage
[ ? ] gpm
[ ? ] hdparm
[ - ] hostname.sh
[ ? ] hwclock.sh
[ ? ] hwclockfirst.sh
[ ? ] ifupdown
[ ? ] ifupdown-clean
[ ? ] kexec
[ ? ] kexec-load
[ ? ] keyboard-setup
[ ? ] keymap.sh
[ ? ] killprocs
[ ? ] klogd
[ ? ] knoppix-autoconfig
[ ? ] knoppix-halt
[ ? ] knoppix-reboot
[ ? ] knoppix-startx
[ ? ] loadcpufreq
[ ? ] lvm2
[ ? ] mdadm
[ ? ] mdadm-raid
[ ? ] module-init-tools
[ ? ] mountall-bootclean.sh
[ ? ] mountall.sh
[ ? ] mountdevsubfs.sh
[ ? ] mountkernfs.sh
[ ? ] mountnfs-bootclean.sh
[ ? ] mountnfs.sh
[ ? ] mountoverflowtmp
[ ? ] mtab.sh
[ + ] network-manager
[ ? ] networking
[ - ] nfs-common
[ - ] nfs-kernel-server
[ + ] open-iscsi
[ - ] portmap
[ ? ] pppstatus
[ ? ] procps
[ ? ] rc.local
[ - ] rmnologin
[ - ] rsync
[ ? ] screen-cleanup
[ ? ] sendsigs
[ ? ] setserial
[ - ] smartmontools
[ - ] ssh
[ - ] stop-bootlogd
[ - ] stop-bootlogd-single
[ ? ] sudo
[ ? ] sysklogd
[ ? ] udev
[ ? ] udev-mtab
[ ? ] umountfs
[ ? ] umountiscsi.sh
[ ? ] umountnfs.sh
[ ? ] umountroot
[ - ] urandom
On a Microknoppix system, such as may be present on a Rescue CD or
other live CD or
DVD, the SSH server software may not even be present on the CD or DVD. You
can use the apt-cache search command followed by a
regular
expression, in this case ssh, to determine if
the package is present on the system.
root@Microknoppix:/# apt-cache search ssh
libssl0.9.8 - SSL shared libraries
sshstart-knoppix - Starts SSH and sets a password for the knoppix user
openssh-client - secure shell (SSH) client, for secure access to remote machines
In the case above, I can see that only an SSH client is present. If I run the
sshstart-knoppix command, I will be prompted to set a password for the
knoppix account on the system, but, since the SSH server package is not present,
the command won't actually start an sshd service.
If the SSH server service is not running and the SSH server package
is not installed, first you need to install
the SSH server software. To do so you may need to add an appropriate
package repository, such as http://us.debian.org/debian to
the file /etc/apt/sources.list. E.g., you will need to do
so when using the
F-Secure 3.16
Rescue CD.
If you attempt to install the openssh-server package and
see the results below, then you need to add an appropriate repository
to /etc/apt/sources.list so the system can find the package
and download it.
root@Microknoppix:/# apt-get install openssh-server
Reading package lists... Done
Building dependency tree...
Reading state information... Done
Package openssh-server is not available, but is referred to by another package.
This may mean that the package is missiong, has been obsoleted, or
is only available from another source
E: Package 'openssh-server' has no installation candiate
root@Microknoppix:/#
You can add the http://us.debian.org/debian repository
to the end of the file by using the cat command. Type
cat >> /etc/apt/sources.list (make sure you use two
greater than signs so as to append to the file rather than overwrite it)
then type deb http://http.us.debian.org/debian stable main contrib
non-free and then hit Enter. Then hit the Ctrl
and D keys simultaneously, i.e., Ctrl-D. Next issue the
command apt-get update. When that command has completed,
issue the command apt-get install openssh-server. When
informed of the amount of additional disk space that will be needed and
them prompted as to whether you wish to continue, type "Y". When
prompted "Install these packages without verification [y/N]?",
enter "y".
When the command completes you can then issue the command
netstat -a | grep ssh to verify that the system
is listening on the SSH port, which is normally TCP port 22.
root@Microknoppix:/# netstat -a | grep ssh
tcp 0 0 *:ssh *:* LISTEN
tcp6 0 0 [::]:ssh [::]:* LISTEN
If you issued the command apt-cache search openssh-server
at this point, you would see the following:
root@Microknoppix:/# apt-cache search openssh-server
openssh-server - secure shell (SSH) server, for secure access from remote machines
Use the passwd command to set the password for
the knoppix account, which you can use for remote logins.
root@Microknoppix:/tmp# passwd knoppix
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Hit Return to continue.
Once the SSH server service is running, you should be able to
connect to the system remotely with an SSH client on another system.
To determine what IP address you should use for the connection, you
can issue the command ifconfig. You should see
an inet addr line that will provide the system's
current IP address. It will typically be in the information
provided for the eth0 network interface. The
l0 interface is the
local loopback interface, which will have an IP address
of 127.0.0.1. You can use that address to verify
that the SSH connectivity is working from the local system,
but not for a remote login.
root@Microknoppix:/# ifconfig
eth0 Link encap:Ethernet HWaddr 00:18:f3:a6:01:8a
inet addr:192.168.0.40 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::218:f3ff:fea6:18a/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:334286 errors:0 dropped:0 overruns:0 frame:0
TX packets:262393 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:289663552 (276.2 MiB) TX bytes:183570787 (175.0 MiB)
Interrupt:23 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:24 errors:0 dropped:0 overruns:0 frame:0
TX packets:24 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2331 (2.2 KiB) TX bytes:2331 (2.2 KiB)To login remotely via SSH, use knoppix for the login
account and provide the password you entered above for that account
when prompted for the password. Once you have logged in under the
knoppix account, you can obtain a Bash shell prompt
for the root account using the command sudo bash.
knoppix@Microknoppix:~$ sudo bash
root@Microknoppix:/home/knoppix#
If you then need to stop, start, or restart the service, you can do
so using /etc/init.d/ssh followed by the appropriate parameter.
root@Microknoppix:/# /etc/init.d/ssh
[info] Usage: /etc/init.d/ssh {start|stop|reload|force-reload|restart|try-restar
t|status}.The configuration file for the SSHD service is
/etc/ssh/ssh_config. You can change values by removing the
comment character, #, from the beginning of a line and chaning the
default value on the line, then stopping and restaring the service. Note:
stopping the sshd service won't disconnect an existing SSH connection, so
you can remotely restart the service with
/etc/init.d/ssh restart without being disconnected.
[/os/unix/linux/knoppix]
permanent link
Sat, Mar 01, 2014 11:28 am
Using multiple conditions with find
The
find command on Unix/Linux and Apple OS X systems allows
you to specify multiple criteria to be used for a search. For instance,
suppose I have a directory named
man and a file named
manual.txt. If I wanted to find any files or directories
containing "man" within their names, I could issue the command below. If
the directory in which the find command was executed contained a subdirectory
named
man and a text file named
manual.txt, I
would see the results shown below:
$ find . -name \*man\*
./man
./manual.txt
Note: the backslashes before the asterisks are
"escape characters",
i.e., they tell the shell not to interpret the asterisk before the find
command sees it - see
What is the difference between \*.xml and *.xml in find command in Linux/mac.
Another alternative is to enclose the *man* within double quotes.
$ find . -name "*man*"
./man
./manual.txt
But, if I only want to find items that have "man" in the name which are
directories, I could use the following to specify I only want to see items
where the file is of type directory ("d" represents directory and "f" represents
a regular file):
$ find . -name \*man\* -type d
./man
By default, the find command will use a
logical and for the two
conditions, i.e., both conditions must be met. I could explicitly state
I want to "and" the two conditions with a -a, but it isn't
necessary to do so in this case.
$ find . -name \*man\* -a -type d
./man
But what if I want to to specify a
logical "or", i.e.
that I want results returned where either of two conditions are met? E.g.,
suppose I want to find all files where the filename contains man
or guide. Then I need to use a -o parameter.
$ find . -name "*man*" -o -name "*guide*"
./man
./manual.txt
./guide.txt
Suppose I only wanted to see only files with man or guide
in the filename that are "regular" files and not any
directories. I could use -type f to specify that I only want
to see regular files.
$ find . -name "*man*" -o -name "*guide*" -type f
./man
./manual.txt
./guide.txt
As you can see, the directory man is still returned. To get
the results I want, i.e., to not have the directory man appear
in the results, I need to enclose the "or" condtions within parentheses.
$ find . \( -name "*man*" -o -name "*guide*" \) -type f
./manual.txt
./guide.txt
Note: you also need to
"escape" the meaning
of ( and ) by preceding them with the backslash
escape character.
Otherwise, you will get an "unexpected token" error message.
$ find . (-name "*man*" -o -name "*guide*") -type f
-bash: syntax error near unexpected token `('And you need to put a space after the left parenthesis and before the
right parenthesis or you will receive an "invalid predicate" error message.
$ find . \(-name "*man*" -o -name "*guide*"\) -type f
find: invalid predicate `(-name'
As another example, suppose I want to find all HTML or PHP files that
contain the word "Geek" within them when the HTML files have a .html
extension and the PHP files have a .php extension on the file names. Then
I need to use a -o between the conditions to specify that
I want to see results if the file has an extension of .html or .php.
$ find . \( -name "*.php" -o -name "*.html" \) -exec grep -i "Geeks" {} /dev/null \;
./temp.php:1Geeks
./temp.html:2GeeksWhenever a file has a name that ends in .html or .php, the file
contents are sent to the grep command for examination. To specify
that I want to use a logical or, the -o is placed between
-name "*.php" and -name "*.html". Again, I also
have to include the two conditions within parentheses to ensure that
the "or" condition is checked before sending the results to grep for
examination of the contents of the files. If the parentheses aren't used,
I would only see one of the files returned.
$ find . -name "*.php" -o -name "*.html" -exec grep -i "Geeks" {} /dev/null \;
./temp.html:2Geeks
[/os/unix/commands]
permanent link

Privacy Policy
Contact